80%
GenAI Development Shift by 2028

Jayanti Katariya
Last Updated: April 03, 2026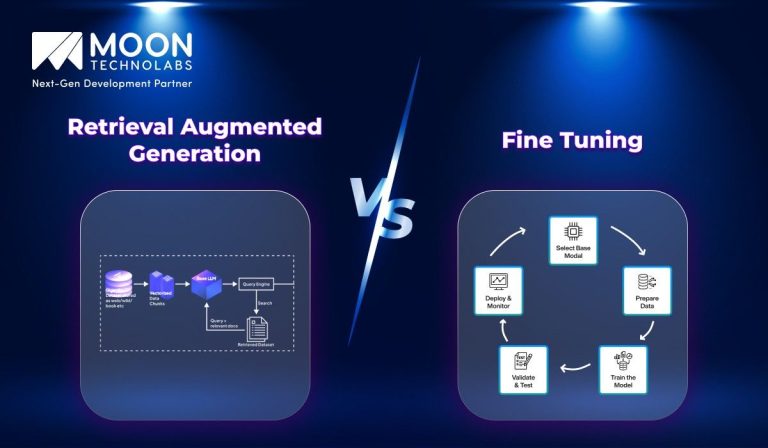
Table of Content
Blog Summary:
Both RAG (Retrieval Augmented Generation) and Fine-Tuning techniques are important for improving AI model performance. RAG brings in real-time external knowledge, while fine-tuning adapts models to specific domains and tasks. This blog provides a brief overview of Retrieval Augmented Generation vs Fine Tuning, compares their strengths, and explains when to use each approach.
Table of Content
As organizations increasingly adopt AI-powered applications, choosing the right approach to optimize model performance has become a critical decision. Two popular techniques, RAG and Fine Tuning, offer distinct advantages depending on the use case, data requirements, and scalability needs. Understanding Retrieval Augmented Generation vs Fine Tuning is essential for building more accurate, scalable, and reliable AI systems. So, let’s get started!
GenAI Platform Adoption Forecast
Organizations are expected to build Generative AI business applications on existing data management platforms by the end of the decade, significantly reducing both development complexity and delivery time.
Retrieval augmented generation (RAG) is an AI approach that combines traditional large language models with external information sources. Instead of relying solely on what the model learned during training, RAG retrieves relevant documents, data, or domain knowledge from external databases in real time to generate more accurate and context-aware responses. This makes it especially useful for answering questions about current events or specialized topics.
By integrating retrieval with generation, RAG helps models provide detailed, up-to-date, and factually grounded model outputs. It is widely used in applications like chatbots, customer support, and research tools, where combining the model’s language skills with real-world knowledge improves reliability and user trust.
RAG is an advanced technique that combines the power of large language models (LLMs) with external knowledge sources, enhancing the accuracy and relevance of generated responses. RAG is particularly useful in scenarios where a model needs to generate answers based on up-to-date or specific domain knowledge. This is too vast for a language model to memorize entirely.
The core process consists of four key steps: Data Ingestion (Indexing), Retrieval, Augmentation, and Generation. Let us discuss them in more detail:
The first step is to gather and organize relevant data from external sources such as documents, research papers, and web pages. This data is indexed by converting it into vector representations, which makes it easy to search for and retrieve relevant information. Preprocessing may also be done to clean and standardize the data.
When a query is made, the system searches through the indexed data to find the most relevant information. The retrieved documents are ranked by their similarity to the query, and the most relevant documents are selected to provide context for the next step.
The retrieved information is combined with the original query to enrich the model’s understanding. This augmented input provides more context, allowing the model to generate a more accurate and informed response. The external data helps address ambiguities and enhances the quality of the response.
Finally, the language model generates a response based on the augmented input. By utilizing both the original user’s query and the external knowledge, the model produces a more detailed, contextually appropriate answer. The output may go through refinement to ensure it is clear and grammatically correct.
Here are the key advantages of Retrieval Augmented Generation, take a quick look at how this approach improves accuracy, relevance, and overall performance:
Retrieval augmented generation improves the reliability of AI-generated responses by grounding them in external data sources. Instead of relying only on pre-trained specialized knowledge, the system retrieves relevant information from trusted documents or databases. This significantly reduces hallucinations and ensures that outputs are more factual and contextually accurate.
One of the key strengths of RAG is its ability to access up-to-date information. Unlike traditional models with a fixed knowledge cutoff, RAG systems can pull current data from APIs, knowledge bases, or document repositories, making them ideal for applications that require real-time insights.
RAG offers a more efficient alternative to retraining large language models. Organizations can update their knowledge base without modifying the RAG model itself, saving both computational costs and development time. This makes it a scalable and practical solution for many businesses.
RAG enhances user trust by providing references or citations alongside its responses. This allows users to verify the source of information, which is especially valuable in domains such as healthcare, finance, and legal services, where accuracy and accountability are critical.
By integrating domain-specific datasets, RAG systems can deliver highly specialized and relevant outputs. This makes them particularly useful for enterprise applications, where tailored domain specific knowledge and precision are essential.
Combine retrieval and customization to build accurate, scalable, production-ready AI systems. With our domain expertise, accelerate deployment and achieve measurable business outcomes.
RAG is transforming how AI systems deliver accurate, context-aware, and real-time responses by combining LLMs with external data sources. Instead of relying solely on pre-trained knowledge, it dynamically retrieves relevant information, significantly improving response quality and reducing hallucinations. This approach enables a wide range of practical applications across industries, some of which are outlined below:
One of the most prominent applications of RAG is in intelligent knowledge bases and conversational AI systems. Traditional chatbots often struggle to deliver up-to-date or generic responses, but RAG-powered chatbots retrieve real-time information from internal databases, FAQs, and documentation to provide precise answers.
This approach enables context-aware customer support, faster query resolution, and more personalized user interactions. Enterprises use RAG to build AI assistants that can instantly access company policies, product manuals, or customer records, significantly improving response accuracy and relevance.
To further enhance chatbot performance, organizations often combine RAG with model fine-tuning, allowing AI systems to adapt to specific domains while still leveraging real-time data retrieval.
RAG is highly versatile and can be tailored to meet the needs of specific industries such as healthcare, finance, legal, and manufacturing. It is especially valuable in sectors where accuracy, compliance, and up-to-date information are critical.
In healthcare, RAG can retrieve medical research and patient data to support better diagnostics. In the legal field, it helps analyze case laws and generate summaries of complex legal documents.
Financial institutions use it to produce real-time insights and market analysis, while manufacturing companies rely on it to access operational data and technical documentation efficiently.
These domain-specific implementations demonstrate how RAG can handle complex queries by grounding responses in verified data sources, making it ideal for high-stakes environments.
RAG significantly enhances content generation by ensuring outputs are factually accurate and contextually relevant. It retrieves reliable data from multiple sources and integrates it into generated content, making it ideal for marketing, reporting, and documentation.
Organizations use RAG architecture to automate report generation, create market research summaries, and develop personalized marketing content. It also plays a key role in knowledge-driven blogging, where accuracy and relevance are essential.
Additionally, RAG enables business intelligence tools to synthesize large volumes of data into actionable insights, helping organizations stay competitive in data-driven environments.
RAG systems play a crucial role in enabling data-driven decision-making by combining real-time data retrieval with AI-generated insights. This allows organizations to make informed decisions based on the latest available information rather than static datasets.
It improves the accuracy and reliability of insights, enables faster analysis of large datasets, and delivers context-rich reporting for executives. This makes it particularly valuable in dynamic business environments where timely decisions are critical.
With the integration of AI into strategic processes, businesses are increasingly leveraging AI solutions to enhance decision-making, forecasting, risk assessment, and operational efficiency.
By grounding AI outputs in real-world data, RAG ensures that decisions are not only intelligent but also trustworthy and aligned with current business conditions.
You May Also Like:
RAG Use Cases: Unlocking the Power of Retrieval-Augmented Generation
Fine-tuning in language models is the process of taking a pre-trained model (one that has already learned general language patterns from large datasets) and training it further on a smaller, specific dataset.
This helps the model adapt to particular tasks, such as sentiment analysis, translation, or answering domain-specific questions. Instead of learning from scratch, the model refines its existing knowledge to perform better in a targeted area. This approach is useful because it saves time and computational resources while improving model performance on specialized tasks.
For instance, a general language model can be fine-tuned on medical or legal texts to better understand those fields. Extensive fine tuning allows developers to customize models for specific applications while maintaining the strong language understanding gained during pre-training.
Explore how fine-tuning works in practice, here’s a brief look at the process used to tailor models for specific needs and better results:
Traditional fine-tuning begins with preparing a dataset tailored to the target use case. Domain reliance is essential, as the data should reflect the specific task, such as medical or legal content. High-quality, well-labeled domain specific data is more valuable than large, noisy datasets. Typically structured as input-output pairs, this data helps the model learn domain-specific patterns and improve its specialization.
During fine tuning, the model’s internal weights are adjusted to improve performance on the new task. Instead of replacing prior knowledge, the model refines it through gradient-based learning. It compares predictions with correct outputs and updates accordingly. Using low learning rates ensures gradual changes, preventing overfitting while maintaining a balance between general knowledge and task-specific accuracy.
Fine tuning also focuses on optimizing the model for a specific task, such as classification or summarization. Performance is evaluated using metrics such as accuracy or F1 score. Hyperparameters such as learning rate, batch size, and number of training epochs are tuned to improve results. The model is tested on new data and refined iteratively to ensure consistent and reliable performance.
Fine-tuning is a powerful approach in ML that adapts a pre-trained model to perform better on specific tasks or domains. It plays a key role in modern machine learning development, offering several practical advantages that make it widely used across industries.
Fine tuning significantly reduces both development time and cost compared to training a model from scratch. Since the base model is already trained on large datasets, only incremental training is required. This means fewer computational resources, faster deployment, and lower infrastructure expenses, making it especially beneficial for startups and teams with limited budgets.
Fine tuning the model on task-specific data further improves accuracy and overall performance. The model becomes better aligned with the nuances of the target task, leading to better predictions, more relevant outputs, and fewer errors than a generic pre-trained model alone.
Fine tuning allows models to specialize in particular domains such as healthcare, finance, legal, or customer support. By exposing the model to domain-relevant datasets, it learns industry-specific terminology, context, and patterns, enabling it to deliver more precise and meaningful results.
Organizations can guide model behavior during fine-tuning by using carefully curated datasets. This helps enforce desired tone, style, and response patterns while minimizing unwanted or biased outputs. As a result, the model becomes more reliable and aligned with organizational or ethical standards.
Fine-tuning can be performed using private or proprietary datasets, allowing organizations to keep sensitive information secure. Instead of relying solely on external data sources, businesses can train models within controlled environments, ensuring compliance with data protection regulations and safeguarding confidential information.
Fine-tuning large language models enables organizations to adapt general-purpose AI to domain-specific needs. By training models on specialized datasets, businesses can significantly improve accuracy, relevance, and efficiency across a wide range of applications:
In clinical documentation and note-taking, fine-tuned models help healthcare professionals streamline recording patient information. These models can convert doctor-patient interactions into structured medical notes, generate discharge summaries, and assist with clinical documentation.
This reduces administrative workload and allows medical practitioners to focus more on patient care while maintaining accuracy and consistency.
In the domain of credit scoring and risk assessment, fine-tuned models analyze financial data, customer behavior, and transaction histories to evaluate creditworthiness. They enable faster, more reliable lending decisions while also improving the detection of fraudulent activity.
By adapting to specific financial contexts, these models enhance both risk management and operational efficiency.
Personalized recommendations are another key application of fine-tuning. By learning from user preferences, browsing behavior, and past interactions, models can deliver highly relevant product, content, or service suggestions.
This improves user engagement, enhances customer experience, and drives higher conversion rates across industries such as e-commerce, streaming platforms, and digital services.
In predictive maintenance, fine-tuned models are applied in manufacturing and industrial settings to monitor equipment performance and predict potential failures. By analyzing sensor data and maintenance records, these models help organizations schedule maintenance in a timely manner, reduce downtime, and extend the lifespan of machinery.
This leads to cost savings and more efficient operations.
Understanding the trade-offs between retrieval-based methods and model customization is essential when building modern AI systems. This comparison of fine tuning vs rag provides a clear overview of how each approach works and where they stand apart:
| Criteria | RAG | Fine Tuning |
|---|---|---|
| Data Dependency | Requires a large, well-structured knowledge base or documents—less dependency on labeled data for supervised learning. | Requires high-quality, task-specific labeled datasets. Performance depends heavily on dataset size and quality. |
| Data Freshness | Very high. The knowledge base can be updated independently, allowing the model to access the latest information. | Low to medium. Retraining the model to incorporate new information is resource-intensive. |
| Implementation Complexity | Medium. Involves integrating retrieval systems with language models and managing indexing. | High. Requires careful model training, hyperparameter tuning, and evaluation. |
| Cost and Resources | Lower for updates; ongoing retrieval costs, but no full retraining needed. | Higher. Fine-tuning large models requires significant computing resources and time. |
| Scalability | Highly scalable. Can handle large and growing knowledge bases without retraining the model. | Limited scalability. Each new domain or update may require retraining or additional fine-tuning. |
| Accuracy and Performance | Good for up-to-date factual queries and broad coverage. May struggle with nuanced reasoning beyond retrieved context. | High for specialized tasks. It can achieve very precise performance on domain-specific tasks if trained well. |
| Maintenance Requirements | Moderate. Focus on keeping the knowledge base up to date and optimizing the retrieval system. | High. Needs retraining with new data, monitoring for model drift, and occasional hyperparameter adjustments. |
| Security and Compliance | Data stays in the knowledge base; sensitive data can be restricted at the retrieval level. | Fine-tuned model may memorize sensitive data; requires careful data handling and access control. |
Understand how Retrieval Augmented Generation and Fine-Tuning differ, here’s a concise look at what sets them apart and when to use each approach:
Retrieval-Augmented Generation (RAG):
RAG systems fetch information from external data sources (e.g., databases, vector stores, APIs) at query time. This means they can access up-to-date and dynamic data without retraining the model. Simply updating the knowledge base is reflected in responses immediately.
Fine-Tuning:
Fine-tuned models rely on static training data. Once trained, their knowledge is frozen and does not change unless the model is retrained. Keeping data fresh requires repeated fine-tuning cycles, which can be costly and time-consuming.
Summary:
RAG excels in real-time accuracy; fine-tuning struggles with evolving information.
Retrieval-Augmented Generation (RAG):
RAG involves multiple components, including document ingestion pipelines, embedding models, vector databases, retrieval mechanisms, and prompt orchestration, which makes it more complex to design, integrate, and maintain, especially in production environments.
Fine-Tuning:
Fine-tuning is comparatively straightforward, as it primarily requires preparing a labeled dataset, training or fine-tuning the model, and deploying it, resulting in a simpler architecture and easier maintenance.
Summary:
RAG has higher system complexity; fine-tuning is simpler architecturally.
Retrieval-Augmented Generation (RAG):
RAG’s performance depends on the quality of document retrieval; when relevant documents are successfully retrieved, responses are accurate and well-grounded, but latency can be higher due to retrieval steps, and poor retrieval can lead to weaker outputs.
Fine-Tuning:
Fine-tuned models provide faster inference since there is no retrieval step, deliver more consistent responses, and perform well on narrow or specialized tasks, but they may produce hallucinations if the knowledge they were trained on becomes outdated.
Summary:
Fine-tuning is faster and more consistent; RAG is more accurate when retrieval is strong.
Retrieval-Augmented Generation (RAG):
RAG scales efficiently with growing data, as new documents can be added to the knowledge base without retraining the model, and large, evolving datasets can be handled with ease, although scaling the supporting infrastructure, such as vector databases and indexing systems, introduces additional operational overhead.
Fine-Tuning:
Fine-tuning is less flexible in terms of scalability, as it requires larger training datasets, greater computational resources, and periodic retraining to incorporate new information, making it less suitable for rapidly growing or frequently changing data.
Summary:
RAG scales better as knowledge expands; fine-tuning scales poorly with data growth.
Retrieval-Augmented Generation (RAG):
RAG allows controlled access to data: information can remain in secure storage, and access can be restricted at query time, ensuring sensitive data is not embedded directly into model weights. However, improper retrieval controls may still expose confidential information.
Fine-Tuning:
Fine-tuning embeds knowledge directly into the model, making it harder to remove sensitive information once trained, increasing the risk of unintended data leakage, and providing less granular control over who can access specific data.
Summary:
RAG offers better data governance and control; fine-tuning carries a higher risk of data exposure.
Our team can guide you in leveraging RAG and fine-tuning it to create reliable, production-ready AI solutions tailored to your business.
Retrieval Augmented Generation enhances language models by connecting them to external data sources, allowing them to generate more accurate and up-to-date responses. It is particularly useful in scenarios where access to current, domain-specific, or frequently changing information is essential, as highlighted in the use cases below:
RAG is useful when your data changes frequently, such as news, policies, or product information. Instead of retraining the model every time data updates, RAG retrieves the latest information in real time, ensuring responses stay current.
When you don’t have enough data to train or fine-tune a model, especially in specialized domains, RAG can pull relevant information from existing documents or databases, making it a cost-effective solution for niche or proprietary knowledge.
RAG is ideal for applications where accuracy is critical, such as healthcare, legal, or enterprise systems. Grounding responses in retrieved data reduces the chances of incorrect or misleading answers.
Fine-tuning is a powerful technique for adapting a pre-trained language model to perform specific tasks or meet particular requirements. Below are the key scenarios where fine-tuning is more effective:
Fine tuning requires domain knowledge for specialized tasks, such as legal, medical, or technical fields. It enables better understanding of terminology, context, and patterns, improving accuracy, relevance, and task-specific performance.
Apply fine-tuning to improve model performance by correcting errors, increasing consistency, and aligning outputs with desired tone or format. It helps when base models generate generic, inconsistent, or less accurate responses.
Consider fine-tuning when working under resource constraints, allowing smaller models to handle specific tasks efficiently. This reduces computational costs, improves response speed, and supports scalable, cost-effective deployment in production environments.
When comparing fine tuning vs retrieval augmented generation, the right choice ultimately depends on your specific needs: RAG is ideal for dynamic, up-to-date, and verifiable information, while fine-tuning excels at delivering consistent behavior and domain-specific expertise.
Rather than viewing them as competing approaches, many modern AI systems combine both, leveraging fine-tuning to shape responses and RAG to inject current, relevant knowledge, resulting in more scalable, accurate, and reliable solutions.
01
02
03
04

Jayanti Katariya is the CEO of Moon Technolabs, a fast-growing IT solutions provider, with 18+ years of experience in the industry. Passionate about developing creative apps from a young age, he pursued an engineering degree to further this interest. Under his leadership, Moon Technolabs has helped numerous brands establish their online presence and he has also launched an invoicing software that assists businesses to streamline their financial operations.
Submitting the form below will ensure a prompt response from us.
We refine our expertise to deliver innovative business solutions.




205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United States
13500 Long Is Dr, Pflugerville, TX 78660, USA
C/105 Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060
Ayse D.
Co-Founder“ I highly recommend Moon Technolabs as the quality of service is wonderful. We have hired this company to develop the product based on some complex & technical issues. We get the best quality services as compared with others in the market. Huge Thanks to Moon Technolabs as the team is always ready to give the solution all time.”
Justin G.
Founder & CEO“ Moon Technolabs is a pioneer in the WebRTC based project as they have fixed complicated segments of the module by fulfilling different product lines by providing 24X7 customer support. We really recommended Moon Technolabs as they are able to develop products as per the module deadline and project timeline.”
Flavio S.
Founder & Managing Director“I am happy to recommend Moon Technolabs for their app development services. They successfully developed apps for me, and I am highly satisfied with the overall outcomes. The development team has swiftly addressed the issues with responsive and effective communication to understand the requirement quickly and actively resolve the back-and-forth problems that arose...”
Jay M.
Founder & CEO“Moon Technolabs is the best company that provides advanced apps and websites development services in the USA and Europe. I am a newbie to develop my app with an external team. I am really happy to work with them as I am not that much mobile apps user. Here, the team and specially the CEO of Moon Technolabs helps me to let me know about the benefits of my app to generate revenue....”




Our Offices
India
C/105 Ganesh Meridian,S.G. Highway, Ahmedabad, GJ 380060USA
205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United StatesContact Information