
 Total View: 407
Total View: 407

Submitting the form below will ensure a prompt response from us.
In the world of machine learning, especially in classification problems, evaluating a model’s performance is just as important as building the model itself. Accuracy alone cannot always provide a complete picture, particularly when dealing with imbalanced datasets. That’s where evaluation metrics such as precision, recall, and F1-score come into play. What is Recall in Machine Learning? It’s a metric that focuses on how well a model can identify positive instances, making it particularly useful in cases where false negatives are costly.
This article will focus on Recall in Machine Learning, what it is, why it matters, how it is calculated, and how you can implement it in Python.
Recall (also known as Sensitivity or True Positive Rate) measures how well a model can identify positive cases out of all actual positive cases in a dataset.
In simpler terms, recall answers the question:
👉 Out of all the actual positive cases, how many did the model correctly identify?
It is particularly useful in scenarios where missing positive cases can be very costly, such as:
The mathematical formula for recall is:
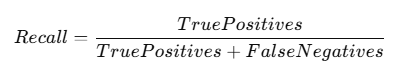
Where:
A higher recall means the model is successfully capturing more positive cases.
To better understand recall, let’s consider the confusion matrix of a binary classification model:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
Imagine a model designed to predict whether a patient has a particular disease:
Let’s say we are building a medical model to detect diabetes.
Here’s the confusion matrix breakdown:
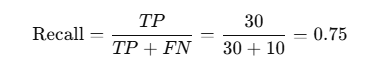
So, the recall is 75%. This means the model detects 75% of all diabetic patients, but misses 25%.
Let’s see how to compute recall using Python and scikit-learn:
from sklearn.metrics import recall_score
# Actual labels
y_true = [1, 0, 1, 1, 0, 1, 0, 0, 1, 1]
# Predicted labels
y_pred = [1, 0, 1, 0, 0, 1, 0, 1, 1, 0]
# Calculate Recall
recall = recall_score(y_true, y_pred)
print("Recall Score:", recall)
Recall Score: 0.7142857142857143
Here, the recall is approximately 71.4%, meaning the model correctly identified about 71% of all actual positive cases.
Recall is often compared with Precision, which focuses on the correctness of positive predictions.
👉 In applications like spam detection, precision is more important (you don’t want to mark genuine emails as spam).
👉 In medical diagnosis, recall is more important (better to flag more patients than to miss one).
Sometimes, focusing solely on recall can result in a high number of False Positives. To balance both Precision and Recall, we use the F1-Score, which is the harmonic mean of the two.
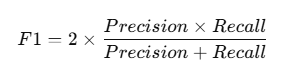
This ensures the model does not overly sacrifice precision for recall.
Recall becomes the top priority in scenarios where missing a positive instance has severe consequences. Examples include:
In such use cases, recall ensures we minimize False Negatives, even if it means slightly increasing False Positives.
Precision, recall, and F1 score are critical for accurate AI models. Let our experts help you apply the right metrics to improve your machine learning projects.
Recall in machine learning is a critical metric that measures how effectively a model can detect positive cases among all actual positives. It plays a key role in domains where missing positive outcomes is risky or costly.
By understanding recall, how it’s calculated, and how to implement it in Python, data scientists and machine learning engineers can make better decisions when building and evaluating models.
👉 Remember: A good machine learning evaluation doesn’t rely on a single metric—recall should be analyzed alongside precision, accuracy, and F1-score to gain a complete understanding of model performance.

Jayanti Katariya is the CEO of Moon Technolabs, a fast-growing IT solutions provider, with 18+ years of experience in the industry. Passionate about developing creative apps from a young age, he pursued an engineering degree to further this interest. Under his leadership, Moon Technolabs has helped numerous brands establish their online presence and he has also launched an invoicing software that assists businesses to streamline their financial operations.
Submitting the form below will ensure a prompt response from us.
We refine our expertise to deliver innovative business solutions.




500 N Michigan Avenue, #600, Chicago IL 60611
13500 Long Is Dr, Pflugerville, TX 78660, USA
C-105, Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060
Ayse D.
Co-Founder“ I highly recommend Moon Technolabs as the quality of service is wonderful. We have hired this company to develop the product based on some complex & technical issues. We get the best quality services as compared with others in the market. Huge Thanks to Moon Technolabs as the team is always ready to give the solution all time.”
Justin G.
Founder & CEO“ Moon Technolabs is a pioneer in the WebRTC based project as they have fixed complicated segments of the module by fulfilling different product lines by providing 24X7 customer support. We really recommended Moon Technolabs as they are able to develop products as per the module deadline and project timeline.”
Flavio S.
Founder & Managing Director“I am happy to recommend Moon Technolabs for their app development services. They successfully developed apps for me, and I am highly satisfied with the overall outcomes. The development team has swiftly addressed the issues with responsive and effective communication to understand the requirement quickly and actively resolve the back-and-forth problems that arose...”
Jay M.
Founder & CEO“Moon Technolabs is the best company that provides advanced apps and websites development services in the USA and Europe. I am a newbie to develop my app with an external team. I am really happy to work with them as I am not that much mobile apps user. Here, the team and specially the CEO of Moon Technolabs helps me to let me know about the benefits of my app to generate revenue....”




Our Offices
India
C-105, Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060USA
500 N Michigan Avenue, #600, Chicago IL 60611Contact Information








