
Jayanti Katariya
Last Updated: March 05, 2026
Table of Content
Blog Summary:
MLOps helps teams streamline the development, deployment, and management of ML models with automation and continuous monitoring. Businesses implementing AI-driven models must adopt MLOps to handle data changes, quality, and deployment complexity efficiently in its lifecycle. This blog explores why MLOps is essential in a model’s lifecycle, its components, and the solutions for real-world ML challenges.
Table of Content
Machine Learning Operations (MLOps) was born at the intersection of data engineering, DevOps, and machine learning. However, ML systems are highly experimental and, hence, even more complex to build, operate and execute.
While ML provides plenty of ideas and theories for data scientists and engineers to explore, the reality is far more serious. When developing an MLOps Lifecycle for an ML model in real-life business situations, many essentials need to be considered:
Most importantly, you need to find solid and fundamental ways to scale your ML operations based on your business’s needs and the ML model’s users. With MLOps, your business strikes the right balance in the communication between the operations and science departments.
In this blog, we’ll explain how an MLOps lifecycle works and its key components by using different types of recommendation systems as examples.
MLOps stands for Machine Learning Operations. It is a set of practices that helps engineers and data scientists automate the lifecycle of a machine learning model that is ready to be deployed.
MLOps is very similar to DevOps because the latter’s principles heavily influence the former’s. Yet, there are many notable differences between the two.
MLOps requires extensive feature tweaking by a hybrid team that might not possess software engineering skills. The pipeline also has multiple steps to train and deploy, and many manual steps need to be automated.
Building production-class environments while also monitoring data and the codebase can often degrade performance due to evolving data profiles. Eventually, mishandling the data discrepancies can create model decay, which requires continuous monitoring for rollbacks.
Unlike DevOps, continuous integration and deployment in the MLOps lifecycle also involve validating data and models in addition to code and components. With continuous testing (CT) added to this mix for retraining and serving, ML becomes quite different from DevOps.
However, these goals are difficult to achieve without a framework. Hence, access to expert MLOps consulting services is crucial for today’s businesses that want to build and deploy AI models.
It serves as a map for developers and managers to bring models faster to the market, boost efficiency, and tap into undiscovered revenue streams at lower operating costs.
Are you struggling with building, deploying, and managing the workflows of your ML models to scale them efficiently?

Let’s understand machine learning operations with an example. Suppose you want to deploy a recommendation engine system with the MLOps lifecycle for travel products, services, and content based on user preferences.
MLOps will help you automate data ingestion from sources like user preferences, bookings, and location data to prepare structured and clean data. You can then use this data for feature engineering by extracting the budget, weather, and destination history.
MLOps will help you choose the right ML algorithm for personalized recommendations.
For instance, you can build a Weighted Hybrid Model that uses a mix of content-based and collaborative filtering algorithms, such as Neural Collaborative Filtering (NCF) and Cosine Similarity.
As the next step of this ML model lifecycle, MLOps will help you track the experiments to train the model with MLflow. You can then compare performances to apply automated retraining based on new travel trends or seasonal data.
MLOps will ensure that your recommendation model is accessible through APIs using a fast model serving tool like FastAPI or TensorFlow. Using containerization tools like Docker and Kubernetes, you can deploy and automate it using CI/CD with Jenkins or GitHub Actions.
With real-time monitoring, machine learning operations can help you track the accuracy of recommendations. Using tools like Prometheus and Grafana, you can then update the model based on feedback on user behavior, such as bookings and engagement.
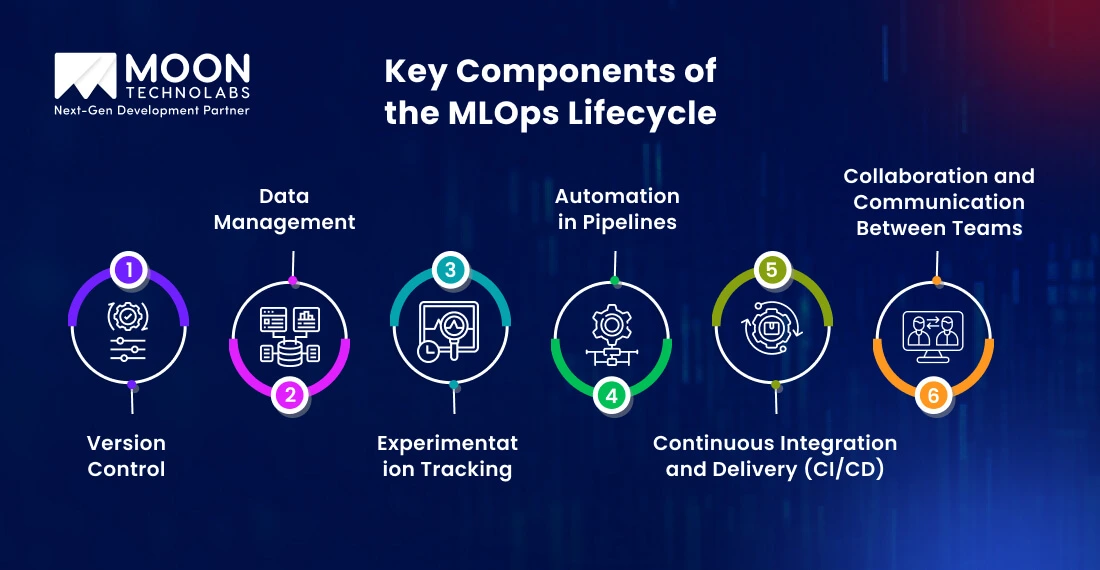
Let’s understand the key components of the MLOps lifecycle of building different types of personalized recommendation systems. These are based on the type of datasets and how they are processed to serve as a base for predictions.
Version control helps track changes in user interactions. It also helps you control different versions of data and track improvements in algorithms, codebases, and pipelines.
For instance, you are using Collaborative Filtering (CF) to build a movie recommendation system and have 2 different versions. If the basic version with rating-based recommendations doesn’t perform, you can switch to genre-based filtering to increase engagement using rollbacks.
For example, an online reading platform builds a book recommendation system that gathers diverse structured and unstructured data. Data management will ensure that raw data from book views, reading duration, reviews, wishlists, authors, and social media interactions is processed.
MLOps lifecycle replaces missing values, removes duplicates, and normalizes text data using Pandas and Spark for large-scale processing. It also optimizes faster database query lookups with Redis and Memcached.
Lastly, it uses governance policies with AWS IAM and Azure Security to protect user interactions, limit and track who has access, and mask sensitive data.
Testing multiple experiments with different algorithms, hyperparameters, features, and variations ensures that all insights are saved and successful results are produced.
For example, a travel recommendation platform uses a hybrid model that suggests flights, stays, and activities using two different filtering algorithms.
Tracking experiments in an MLOps lifecycle enables you to test which algorithm, model, or set of features gives the best results for location, history, and seasonal trends. By tracking experiments side-by-side, you can also find the best combinations for different user groups.
A well-structured pipeline of model deployment requires efficient handling of new bookings, searches, and reviews in real time. For example, a user books a new beachside hotel.
Batch and real-time processing tools like Kafka and Apache Airflow allow you to update the recommendation model according to new preferences. With new data, you can automate the comparisons of the model performance without any downtime and retrain it as the trends shift.
CI/CD tools ensure that real-time personalization deploys new machine learning operations models without breaking the recommendation engine. Using tools like Jenkins and ArgoCD, you can gradually release the updated models into production for smaller groups.
For example, users have started preferring economy flights. The model detects this and triggers a new training run to retrain it using drift detection tools like EvidentlyAI and WhyLabs, showing budget-friendly flights.
Collaboration between data scientists, software developers, and ML engineers is essential to ensure that models remain current and pipelines remain functional.
For example, teams are facing challenges in comparing different model versions of an MLOps lifecycle and discussing improvements to integrate recommendations into booking systems. MLOps provides Playbooks and Standard Operating Procedures (SOPs) to help teams access guidelines for updating the model.
Automate your AI/ML model data pipelines with minimum downtime to enhance data quality, scalability, and deployment.
The lifecycle of ML-powered recommendation systems is complex because teams have to move the model from the experimentation stage to production manually. According to a survey by Cnvrg.io, teams spend 65% of their time on engineering non-data science tasks like tracking, monitoring, and configuring, often creating technical debt.
While machine learning operations automate these things, it also creates challenges in controlling different versions and maintaining a consistent environment across all the stages. Let’s understand some of the common challenges and how to solve them with the best MLOps tools:
ML models can soon become outdated because teams might often fail to feed new and fresh data. Since user preferences change due to trends, new launches, and user behavior, the models won’t increase engagement.
For example, an e-commerce recommendation system keeps working on outdated data and fails to recommend new products.
Solution: Utilize continuous model monitoring to detect drifts in data and trigger automated retraining. Popular tools you can use include Kubeflow and Great Expectations.
ML models and platforms grow exponentially because of new user interactions. In 2024, at least 402.74 million terabytes of data were generated every day. Hence, ML systems often encounter performance issues when teams plan to scale them.
Solution: You can implement distributed computing to handle large-scale datasets and use efficient retrieval techniques to reduce latency. Popular tools include TensorRT and Apache Spark.
Building ML models can often contain missing values, biases, and incorrect assumptions, which can result in inaccurate predictions. For example, a healthcare recommendation system suggests wrong treatments due to misjudged patient history data.
Solution: You can implement automated data validation pipelines of an MLOps lifecycle to fix missing values and apply bias detection to ensure fairness and accuracy. Popular tools you can use include Deequ and AI Fairness 360.
Integrating different types of filtering systems into the engine could be complex when deploying an ML system. A major challenge is to maintain minimum downtime while ensuring smooth deployment.
Solution: You can utilize containerized deployments for better portability and implement small releases to validate new models before rolling out full versions. Popular tools include KFServing, Docker, and ArgoCD.
Building great ML models requires more expertise in engineering than machine learning. Since most of the problems faced in these models are related to engineering, it’s essential to make your data pipeline solid until the end.
Most of the gains reaped are from adding common features built with reasonable objectives. Let’s understand some of the best practices that MLOps provides to achieve them:
In an MLOps lifecycle, teams can automate the manual packaging and delivery tasks, increasing their ability to deploy them on demand. It can be implemented at any stage and repeated as many times as necessary without manually connecting to a server.
Since ML involves more components than traditional software, maintaining versions allows for better compliance due to easy tracking. Whether it’s training datasets, configuration files, executable code, or even model artifacts, everything can be easily reassessed.
MLOps automates regular monitoring of the model’s performance to help teams avoid training the model with any unintended behavior or patterns. Since the performance can hugely vary between training and production data, continuous monitoring helps raise alerts if any unintended behavior is observed.
Any ML system often needs to be integrated with other systems. MLOps is a great example of maintaining communication and alignment between all the teams. It helps teams gather outside and inside information, offers specific expertise, methods, and tools, and decreases friction across them.
Code changes introduce many issues that need to be addressed as early as possible. With MLOps, teams can run an automated build script each time they commit a code change. You can configure a server in the development environment to test defects and code quality problems.
Is your organization at the crossroads of trying to stitch together a custom MLOps ecosystem for quick ML model deployment? We understand that your in-house teams could be building an AI/ML model for months as new data keeps coming in, requiring it to be retrained.
In fact, many ready-to-deploy, end-to-end MLOps platforms are available to automate each step, making this process easier for your engineers, developers, and data scientists.
However, is your team ready to build and maintain an in-house solution for years, or is it time to leverage a scalable, cost-effective custom MLOps platform that you can build with your chosen tools?
At Moon Technolabs, we help businesses like yours streamline and scale their machine learning workflows with MLOps consulting services. We are a reputed machine learning development company with the right expertise to guide you whether you need full flexibility or a plug-and-play platform to get started immediately.
Get in touch with our MLOps experts to discuss the best approach.
01
02
03
04
05

Jayanti Katariya is the CEO of Moon Technolabs, a fast-growing IT solutions provider, with 18+ years of experience in the industry. Passionate about developing creative apps from a young age, he pursued an engineering degree to further this interest. Under his leadership, Moon Technolabs has helped numerous brands establish their online presence and he has also launched an invoicing software that assists businesses to streamline their financial operations.
Submitting the form below will ensure a prompt response from us.
We refine our expertise to deliver innovative business solutions.




500 N Michigan Avenue, #600, Chicago IL 60611
13500 Long Is Dr, Pflugerville, TX 78660, USA
C/105 Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060
Ayse D.
Co-Founder“ I highly recommend Moon Technolabs as the quality of service is wonderful. We have hired this company to develop the product based on some complex & technical issues. We get the best quality services as compared with others in the market. Huge Thanks to Moon Technolabs as the team is always ready to give the solution all time.”
Justin G.
Founder & CEO“ Moon Technolabs is a pioneer in the WebRTC based project as they have fixed complicated segments of the module by fulfilling different product lines by providing 24X7 customer support. We really recommended Moon Technolabs as they are able to develop products as per the module deadline and project timeline.”
Flavio S.
Founder & Managing Director“I am happy to recommend Moon Technolabs for their app development services. They successfully developed apps for me, and I am highly satisfied with the overall outcomes. The development team has swiftly addressed the issues with responsive and effective communication to understand the requirement quickly and actively resolve the back-and-forth problems that arose...”
Jay M.
Founder & CEO“Moon Technolabs is the best company that provides advanced apps and websites development services in the USA and Europe. I am a newbie to develop my app with an external team. I am really happy to work with them as I am not that much mobile apps user. Here, the team and specially the CEO of Moon Technolabs helps me to let me know about the benefits of my app to generate revenue....”




Our Offices
India
C/105 Ganesh Meridian,S.G. Highway, Ahmedabad, GJ 380060USA
500 N Michigan Avenue, #600, Chicago IL 60611Contact Information