A Comparative Analysis of HBase Vs Cassandra for NoSQL Database Solutions

Jayanti Katariya
Last Updated: Apr 03, 2026
Table of Content
Table of Content
In the realm of database management, traditional databases have undergone transformative updates, particularly in terms of flexibility and scalability, as seen in the evolution of NoSQL databases. This adaptation has not only heightened their popularity and acceptance but has also significantly expanded their market size.
In the context of web and app development, the importance of databases cannot be overstated. Serving as the foundational repository for organizing, storing, and retrieving data, databases play a pivotal role in ensuring the seamless functionality and performance of any web or app development project.
As per research, the overall market size of NoSQL was valued at $7.3 billion in 2022 and is expected to go up to $86.3 billion by 2032. HBase and Cassandra are the two most robust NoSQL databases that are equally popular for having their own set of advantages. Therefore It makes the comparison of HBases vs Cassandra mandatory.
While selecting the right option between these two databases you need to take into account a number of factors like scalability, support, agility, read & write performance, application workloads, etc. Here, Let’s compare HBase vs Cassandra in detail which help you select the right one. Let’s delve into it.
What is Hbase?
HBase, open-source, is a NoSQL database designed specifically to handle the largest volume of sparse data. Developed on the top of the Hadoop Distributed File System (HDFS), it provides real-time access to the largest volume of datasets. The architecture of HBase is modeled after Bigtable developed by Google.
It uses a column-family storage model and supports horizontal scalability through the addition of more commodity hardware. HBase is the most appropriate option to use for applications related to analytics, real-time processing, and logging. That’s the reason why it’s the most popular option for many organizations that deal with a huge set of datasets and dynamic workloads in a distributed computing environment.
Components of Hbase
Maintained by Apache, HBase has several components that work together to provide the most powerful data storage solutions. Let’s explore the top components of HBase:
HMaster
HMaster functions as the master server in an HBase cluster, taking on the crucial role of managing metadata and effectively coordinating all applications within the system. It is responsible for handling tasks such as table metadata and schema changes, while also monitoring the health of region servers. Essentially, HMaster plays a key role in overseeing the overall structure and functionality of the HBase cluster.
Region Server
The region server is another major HBase component and is responsible for serving clients with data. Besides, it also includes the ability to manage the actual data storage.
It hosts one or multiple regions where every region is a subset of the overall data. It’s capable of managing reading and writing requests for the assigned regions. Region servers also split the region when it becomes too large.
Zookeeper
Zookeeper serves as a coordinator in a fully distributed HBase environment. It’s a good option to maintain the server condition inside the cluster by communicating with the help of sessions.
It checks the availability of the server and also whether the server is active or not. In case of server failure, it sends a quick notification. Zookeeper is also responsible for maintaining the path to the META server.
HDFS
When discussing the Hadoop Distributed File System (HDFS), it functions as the primary storage system, efficiently facilitating the swift transfer of data among various nodes. HDFS stands out as a preferred option for companies dealing with vast amounts of data storage and management, thanks to its capability to handle large data volumes effectively.
HBase Architecture
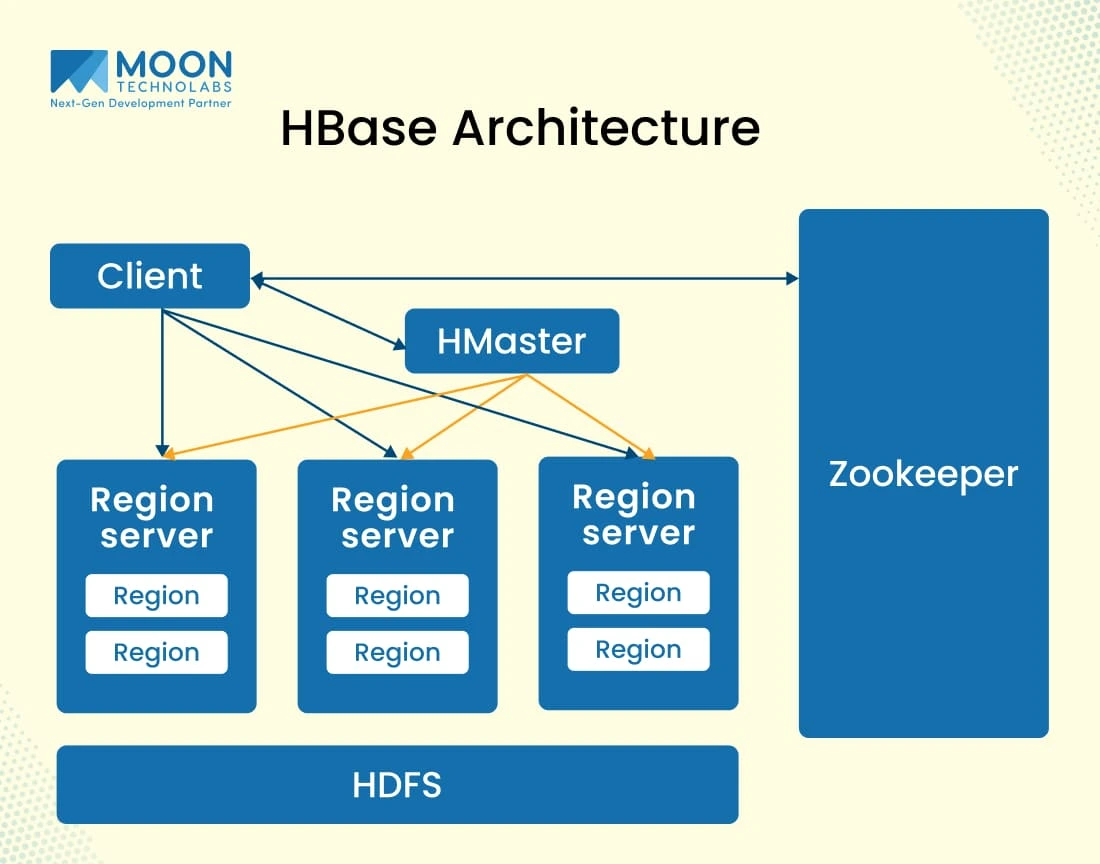
With a scalable and distributed architecture, HBase works based on a master-slave model accompanied by the HMaster managing cluster operations. The data is distributed across multiple regions as tables, which are administered by a RegionServer. Its architecture follows automatic sharing when it comes to horizontal scalability. Besides, it also follows a column-family data model that ensures efficient retrieval and storage.
What is Cassandra?
Cassandra is another NoSQL database system maintained by Apache. It makes the process of handling a vast amount of data across many servers easy even without failure. Be it wider availability, fault tolerance, or linear scalability, the database system is popular for various things. Based on a decentralized architecture, Cassandra ensures a seamless expansion through the integration of multiple nodes into the cluster.
Be it unstructured or semi-structured, it is capable of handling all types of data. That’s the reason why Cassandra is the perfect choice for use on IoT platforms, real-time analytics, recommendation engines, and more. Its decentralized nature ensures powerful data storage and also its retrieval in a fully dynamic environment.
Components of Cassandra
Based on peer-to-peer and decentralized design, Cassandra includes a myriad of components that make it a complete database system. Let’s explore each component in detail:
Node
As one of the major components, Node is the core of the architecture of Cassandra. It acts as an individual server and stores data. The communication between each node takes place based on a peer-to-peer protocol, which treats every node equally rather than master or slave nodes. The core functionality of the node includes data storage, maintaining the cluster’s health, and handling read and write requests.
Data Center
Cassandra brings the possibility of dividing nodes into several data centers. Each data center is located in a different geographical area. Data centers work effectively when it comes to improving fault tolerance and also provide exceptional performance by letting users read and write data in their local area within the same data center.
Cluster
A Cassandra cluster is a collection of different nodes that work together. It ensures higher availability and fault tolerance through distributed data across multiple nodes. As mentioned, Cassandra implements a completely decentralized approach when it comes to managing clusters. It reflects that there’s no single point of control or failure.
Keyspace
Keyspace is another crucial component of Cassandra and plays a vital role in organizing and managing data. Besides, it also defines a higher level of characteristics of the way data is distributed and replicated across the cluster.
Table
Data is organized mainly into tables within a Keyspace, which also serves as a basic unit of storage in Cassandra. Tables facilitate removing and adding columns without impacting the existing data.
Every table is recognized as a main key, which can be combined through one or more columns. The main key is important for both data retrieval and distribution since it determines the way data is partitioned across the cluster.
Cassandra Architecture
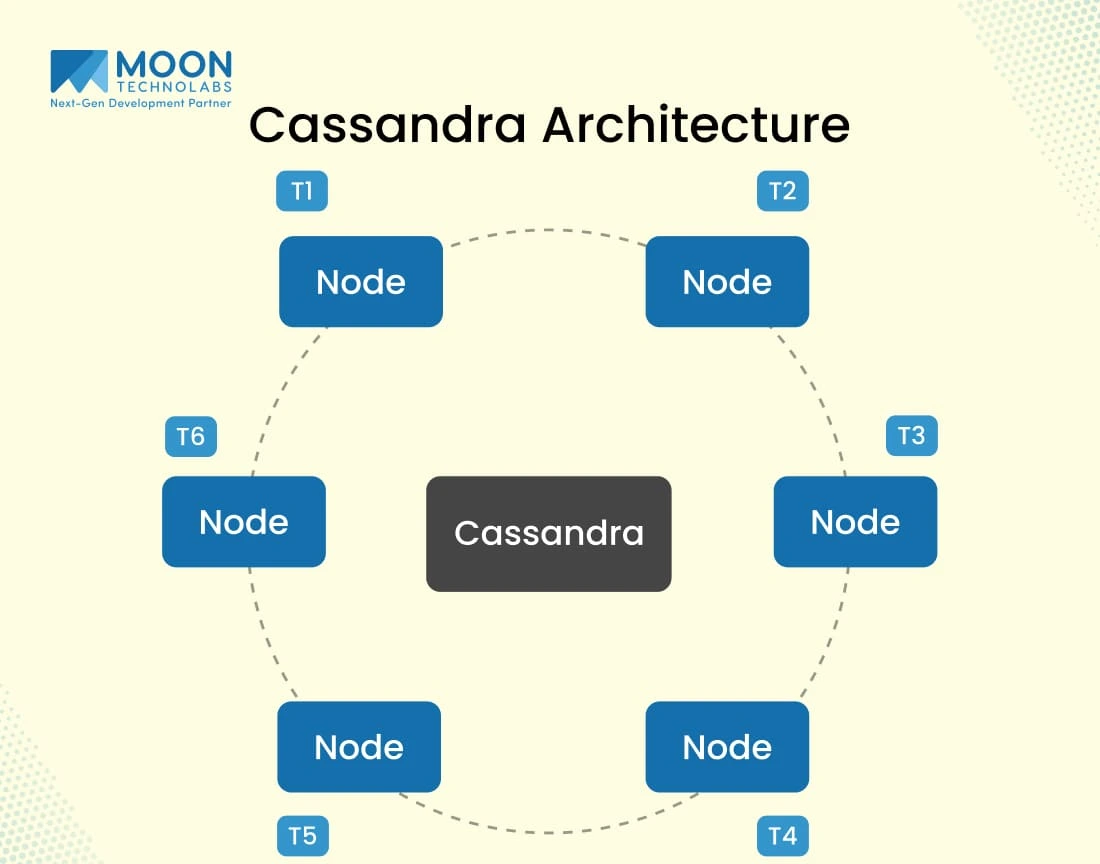
As mentioned, Apache Cassandra has a decentralized architecture, which is highly scalable. The complete architecture system works on a masterless design, which removes the necessity for a centralized coordinator and also improves fault tolerance.
The architecture includes seamless horizontal scaling just by removing or adding nodes dynamically. The decentralized architecture of Apache Cassandra is a perfect choice for handling a larger amount of data with a lower latency performance.
Similarities Between HBase and Cassandra
Though HBase and Apache Cassandra have lots of differences in terms of implementations, these two NoSQL databases also have certain similarities. This is the reason why it emerged as the top choice for various organizations seeking scalable, high-performance, and fault-tolerant data storage solutions.
Let’s explore key similarities:
Distributed and Scalable Architecture
Both HBase and Apache Cassandra can leverage a distributed file system to store data across different nodes, which gives them the ability to handle a large amount of data and also provide complete horizontal scalability. It enables organizations to expand their storage capacity seamlessly and also power by adding several nodes to the cluster.
NoSQL Database Category
Both Cassandra and HBase come under the NoSQL database category, which is a classification that indicates the departure from the traditional relational data models.
These databases are popular for their extraordinary capability of handling both unstructured and semi-structured data with higher efficiency. It makes them a perfect choice that is proper for dynamic and modern applications, which require scalable and flexible data storage.
High Write and Read Throughput
Cassandra and HBase are capable of delivering high write and read throughput. They make it possible by leveraging the distributed architecture that ensures parallel processing of data across various nodes. This parallelism improves the capability of handling numbers of read and write operations concurrently.
Support for Horizontal Scaling
It’s another similarity between HBase and Cassandra, which can scale horizontally by adding nodes to the cluster. This kind of approach emphasizes vertical scaling and is also related to traditional relational databases, which provide flexible and cost-effective solutions to cope with the growing workloads.
Fault Tolerance Mechanisms
Both HBase and Cassandra ensure data availability and integrity through the implementation of fault tolerance mechanisms. They have an enormous capability of replicating data across various nodes, which ensures the system can operate continuously even after the failure of a node. In this process, there’s no data loss.
Explore the HBase vs. Cassandra guide for optimal scalability and performance. Connect with our experts to customize your database solution today!
HBase vs Cassandra: The Differentiation
After similarities, it’s now time to talk about the difference between HBase and Cassandra. You need to know both NoSQL databases differ from each other in certain aspects be it data model, use cases, or architecture.
Let’s have a detailed look at Apache HBase vs Cassandra.
| Features | HBase | Cassandra |
|---|---|---|
| Data Model: Column-Family vs. Wide-Column | It supports a column-family data model | It supports wide-column data model |
| Consistency and CAP Theorem | It supports consistency | It supports tunable consistency, AP system |
| Architecture: Master-Slave vs. Peer-to-Peer | It’s based on master-slave architecture | It’s based on peer-to-peer architecture |
| Write and Read Performance Characteristics | It handles exceptional and balanced read-intensive workloads | Delivers high write throughput, good for write-heavy applications |
| Query Language: HBase API vs. CQL | HBase supports mainly Java-based API for several operations. | Cassandra query language includes CQL which is quite similar to SQL. |
| Storage Mechanism: LSM Tree vs. B-Trees | It works on the LSM Tree storage mechanism | It works on the B-Trees storage mechanism. |
| Scalability Approaches: Automatic vs. Incremental | It ensures automatic scaling. | It provides incremental scaling. |
| Use Cases and Ecosystem Integration | Integration with Hadoop Ecosystem, supporting heavy read workloads. | Integration with distributed database ecosystems and support write-heavy workloads. |
Cassandra or HBase: Which One is the Best Database Model?
Well, both HBase and Cassandra are robust NoSQL databases, which are important in different aspects of database development services. So making the correct choice generally depends on certain specific project requirements.
You should consider deployment needs, structure, and query patterns that are pivotal to determine the best option between these two. You can opt for Cassandra for powerful write operations and wider scalability. On the other hand, HBase is the best option and is appropriate for data consistency in ready-heavy scenarios.
Conclusion
So, after going through the discussion of HBase vs Cassandra, you can see their advantages and limitations. With these details, you can easily decide the right option between these two.
The most crucial factors that you should keep in mind are use cases and specific needs before you finalize any database for your project. It’s advisable to approach a database application development company to get the right assistance in making a selection of the right database.
FAQs
01

Jayanti Katariya is the CEO of Moon Technolabs, a fast-growing IT solutions provider, with 18+ years of experience in the industry. Passionate about developing creative apps from a young age, he pursued an engineering degree to further this interest. Under his leadership, Moon Technolabs has helped numerous brands establish their online presence and he has also launched an invoicing software that assists businesses to streamline their financial operations.
Submitting the form below will ensure a prompt response from us.
We refine our expertise to deliver innovative business solutions.




205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United States
13500 Long Is Dr, Pflugerville, TX 78660, USA
C/105 Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060
Ayse D.
Co-Founder“ I highly recommend Moon Technolabs as the quality of service is wonderful. We have hired this company to develop the product based on some complex & technical issues. We get the best quality services as compared with others in the market. Huge Thanks to Moon Technolabs as the team is always ready to give the solution all time.”
Justin G.
Founder & CEO“ Moon Technolabs is a pioneer in the WebRTC based project as they have fixed complicated segments of the module by fulfilling different product lines by providing 24X7 customer support. We really recommended Moon Technolabs as they are able to develop products as per the module deadline and project timeline.”
Flavio S.
Founder & Managing Director“I am happy to recommend Moon Technolabs for their app development services. They successfully developed apps for me, and I am highly satisfied with the overall outcomes. The development team has swiftly addressed the issues with responsive and effective communication to understand the requirement quickly and actively resolve the back-and-forth problems that arose...”
Jay M.
Founder & CEO“Moon Technolabs is the best company that provides advanced apps and websites development services in the USA and Europe. I am a newbie to develop my app with an external team. I am really happy to work with them as I am not that much mobile apps user. Here, the team and specially the CEO of Moon Technolabs helps me to let me know about the benefits of my app to generate revenue....”




Our Offices
India
C/105 Ganesh Meridian,S.G. Highway, Ahmedabad, GJ 380060USA
205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United StatesContact Information




