MLOps Architecture: Building Scalable and Efficient Machine Learning Systems

Jayanti Katariya
Last Updated: Mar 15, 2026
Table of Content
Blog Summary:
MLOps architecture is vital for building a scalable and efficient machine learning system. One should have complete information regarding MLOps architecture to create such systems. Whether you wish to know about components, workflow, patterns, selection tips, best practices, and more, this post includes complete information regarding MLOps architecture.
Table of Content
The recent stats by Fortune Business Insights show that the global MLOps market is likely to reach up to 13,321 million by 2030, which was $1,064 million in 2023. It shows that organizations are increasingly adopting machine learning for multiple purposes like automating repetitive tasks, decision-making, etc.
So, do you want your organization to build a Machine Learning system to leverage its potential most effectively? Well, the first thing you need to think about is MLOps Architecture. It’s vital to build robust, scalable, and efficient Machine Learning (ML) systems.
MLOps allows your organization to smoothly implement, integrate, and deploy ML models into production environments to automate repetitive processes, monitor them continuously, and ensure reproducibility.
Let’s discuss the architecture in depth.
Importance of a Machine Learning Operation
MLOps is necessary to streamline the lifecycle of different ML models, from development and deployment to maintenance. By integrating ML with many DevOps practices, MLOps offers models that are reproducible, scalable, and reliable in a production environment.
It increases collaboration between different operations and data scientist teams, ensuring version control, efficient experimentation, and monitoring. MLOps’ major advantage is that it reduces deployment time while offering full model accuracy and compliance with organizational standards. It’s useful for discovering model drift and automating different retraining processes.
What is MLOps Architecture?
MLOps architecture is a powerful framework that combines ML and DevOps to improve the monitoring, deployment, and management of ML models in production. Using various tools, processes, and workflows, it simplifies and organizes the collaboration of engineers, scientists, and operations members.
It includes components such as version control, model training pipelines, infrastructure automation, and CI/CD pipelines. This architecture offers reliability, scalability, and reproducibility of different ML models. It also addresses many challenges, such as data inconsistencies and model drift.
The Architecture can speed up ML deployment and optimize the lifecycle of models by minimizing development and operations. By continuously integrating AI solutions, it boosts business value.
Key Components of Architecture
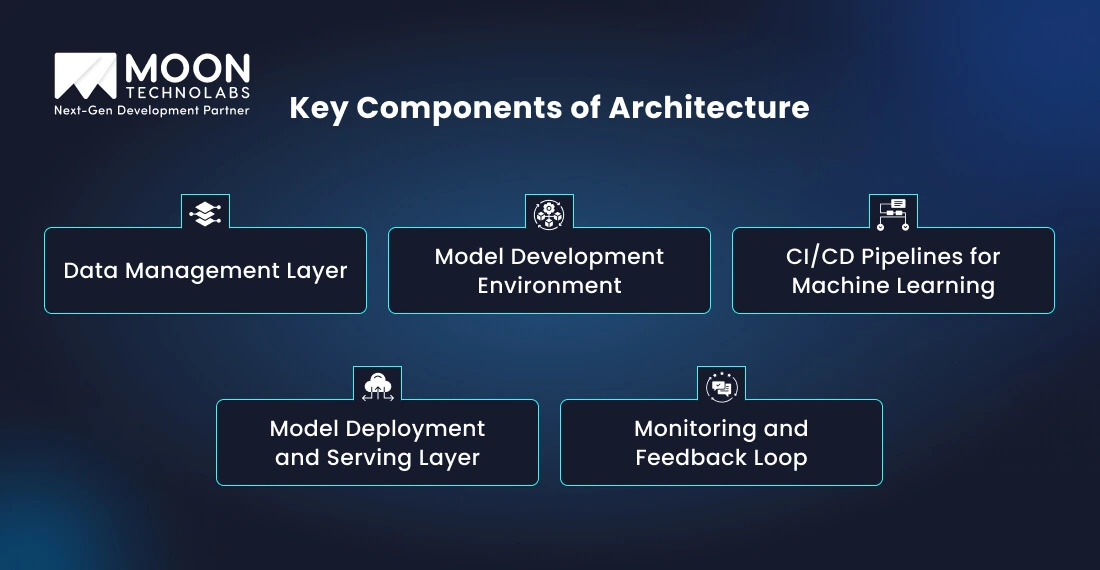
MLOps architecture includes various components that serve specific purposes. Below, we have listed some of the key components in detail. Let’s review them.
Data Management Layer
The data management layer is the foundation of the architecture and includes data preprocessing, collection, storage, and versioning.
Highly effective data pipelines offer top-quality, reproducible, and consistent datasets for evaluation and training. Whether they use Apache Airflow, Apache Kafka, or cloud-based data, these are appropriate for data orchestration and management.
Model Development Environment
With this environment, data scientists get various tools and frameworks necessary for experimentation and model building. These mainly include IDEs and Jupyter notebooks, as well as many frameworks such as PyTorch, TensorFlow, Scikit-learn, and more.
CI/CD Pipelines for Machine Learning
Continuous Integration (CI) ensures that code changes are tested and integrated more efficiently. On the other hand, continuous deployment (CD) automates the entire process of deploying models to production.
ML-based CI/CD pipelines include various steps for model testing, data validation, and automated retraining. The most commonly used tools are KubeFlow Pipeline and Jenkins.
Model Deployment and Serving Layer
This model can deploy models as REST APIs, real-time services, or batch jobs. It offers lower latency, scalability, and reliability. Many popular platforms, such as AWS SageMaker, Kubernetes, or TensorFlow Serving, allow for smooth deployment and model serving.
Monitoring and Feedback Loop
After deployment, models require continuous monitoring for drift, performance, and anomalies. Feedback loops are useful for refining models using real-world data. Many important monitoring tools, such as Grafana, Prometheus, and MLFlow, offer ongoing updates and evaluation.
MLOps Architecture Workflow
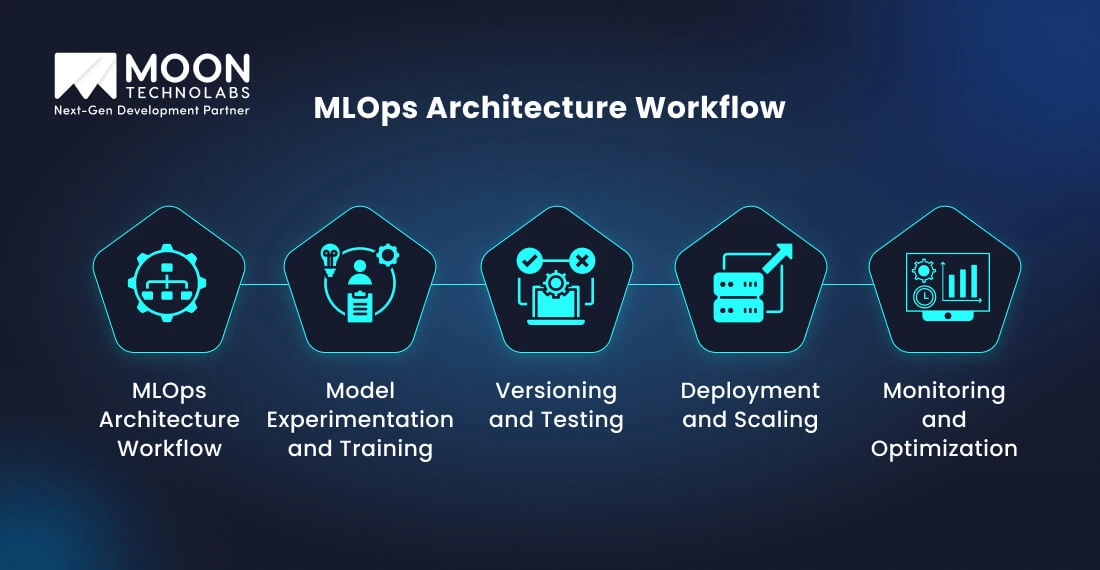
An MLOps architecture workflow includes a range of steps. The following are some of the popular steps in a powerful architecture workflow.
Data Ingestion and Processing
This process starts with data collection from various sources, such as APIs, databases, IoT, or other devices. Then, it is preprocessed to ensure its cleanliness, readiness, and normalization for model training.
Automated pipelines are necessary for handling many risks, such as feature engineering, missing value imputation, data validation, etc. They ensure a reproducible and consistent outcome.
Model Experimentation and Training
This stage mainly focuses on iterative experimentation with a range of hyperparameters and algorithms. Data scientists use various tools and frameworks to create and test models. MLflow and many experiment-tracking platforms are useful for analyzing various performance metrics and comparing outcomes.
Versioning and Testing
Version control is necessary for both models and datasets. Tools such as Data Version Control (DVC) ensure the traceability of every input data, model output, and code. Testing includes verifying robustness, accuracy, and bias to ensure full compliance with the desired benchmarks.
Deployment and Scaling
After the validation process is completed, models are finally deployed using CI/CD pipelines and integrated into production environments like embedded systems or APIs. Many scalable platforms, such as cloud services or Kubernetes, better manage resource allocation. This ensures higher availability and performance, especially during increased demand.
Monitoring and Optimization
Continuous monitoring after deployment is necessary to ensure the model’s accuracy and performance. Feedback loops are created to address data drift, infrastructure issues, and concept drift. After this, automated retraining mechanisms must be implemented to optimize model predictions and keep the system up to date with the latest data.
Parameters to Consider in MLOps Architecture Design
Creating a high-end architecture requires considering several parameters, including reliability, scalability, efficiency, and more. We have covered some of the top parameters here.
Scalability Requirements
Architecture can accommodate the increasing data volume and complexity of different ML models. It should also support horizontal scaling, which ensures a smooth addition of computational resources with increasing demand.
Security and Compliance Standards
Securing sensitive data is necessary. Therefore, architecture must include data encryption, powerful access controls, secure communication protocols, and more.
Any organization handling sensitive data must comply with many industry practices, including HIPAA, GDPR, and others. Various automated security tools that can minimize risks must be regularly integrated and audited.
Cost Optimization Strategies
Better performance is important for managing operations costs. MLOps architectures should be able to compute solutions and provide cost-effective storage, including serverless computing or spot instances.
Many monitoring tools are useful for analyzing various usage patterns. They also ensure cost-saving adjustments, including resource scheduling and auto-scaling.
Team Expertise and Collaboration Needs
The architecture should ensure smooth collaboration among many professionals, such as engineers, data scientists, and operation teams. Tools that support CI/CD pipelines, version control, reproducibility, etc., are highly important. Some of these tools are Jenkins, Git, MLFlow, etc.
Top 3 Popular MLOps Architecture Patterns
When choosing the best MLOps architecture patterns, you will encounter several options. We have discussed three popular patterns here.
Modular Architecture for Flexibility
It segments the MLOps pipeline architecture into independent modules. These models include data ingestions, model training, preprocessing, and deployment. Every module works autonomously, letting teams replace or update various components without interfering with the system.
Ideal For: The modular architecture is the right option for organizations that need a higher level of customization or work with multiple data sources.
End-to-End Pipelines for Efficiency
This architecture can automate the complete lifecycle of ML, from data preparation to model deployment and monitoring. It offers a smooth data flow while minimizing manual intervention and errors.
End-to-end pipelines orchestrate processes using several tools, such as MLflow or Kuberflos, which ensures rapid prototyping and scaling.
Hybrid Models for Custom Solutions
Hybrid architectures can blend cloud-based and on-premise solutions. They address various unique business requirements, such as data security, computational requirements, compliance, etc. This pattern helps organizations maintain a perfect balance of flexibility and control.
6 Steps to Help You Choose the Right MLOps Architecture
Choosing the right architecture is a highly responsible task. To make the best selection, several important factors must be considered. We have covered all those factors in detail here.
Assess Your Organization’s Needs and Goals
First, identify your main goal of deploying machine learning models. Then, define whether you focus on accelerating time to market or managing a larger dataset. This clarity is necessary to ensure the architecture aligns perfectly with your long-term objectives.
Identify Current ML Pipeline Challenges
The next important thing you should consider is understanding challenges in your current ML pipeline, including model deployment delays, inefficiencies in data processing, or a lack of collaboration among teams. Once you address these issues properly, you will know which features to prioritize for your MLOps solution.
Consider Scalability and Automation Requirements
Scalability becomes essential as ML operations grow. It’s essential to determine how the architecture supports the growing volumes of data and models. Besides, automation of many repetitive tasks is important for higher efficiency.
Evaluate Available Tools and Technologies
You need to gather information regarding many popular MLOps tools, such as MLflow, Kuberflow, AWS SageMaker, and many others. You can select ML platforms and tools to deploy and design intelligent algorithms that integrate perfectly with your existing tech stack. They also offer necessary features like monitoring, version control, CI/CD capabilities, and more.
Prioritize Security and Compliance
You should never compromise on security. Make sure the architecture follows the latest regulatory requirements and security standards. Security features such as data encryption, role-based access control, and compliance with many industry regulations are mandatory.
Test and Iterate Before Full Implementation
It’s advisable to start with the pilot project to test the architecture. Make sure you test it in a controlled environment. Before you implement it across your company, you need to gather important feedback, determine gaps, and refine the entire setup accordingly.
Challenges in MLOps Architecture Implementation
You will also encounter many challenges while implementing architecture. Let’s discuss these challenges in depth to avoid them as much as possible.
Managing Data Quality at Scale
MLOps needs to manage a vast amount of data from multiple sources, including different formats, missing values, and inconsistencies. Poor-quality data can cause model failures, inaccurate predictions, significant delays, and more in production cycles.
Implementing automated data systems and continuous monitoring systems can overcome this, but this requires a powerful infrastructure.
Addressing Model Performance Issues Post-deployment
After a final deployment, ML models encounter real-world data, which can also degrade performance. It’s crucial to have a monitoring model for anomalies, drift, and latency issues, but it can also be challenging.
Modern tools and infrastructure are required to create a feedback loop that retains and automates the redeployment process. Failure to address these issues minimizes trust in the entire system.
Aligning Diverse Teams for Smooth Collaboration
Different teams—data scientists, business stakeholders, DevOps professionals, or data engineers—are responsible for handling MLOps. Since they have different expertise and goals, aligning them is quite difficult. Failing to do so can lead to poor workflow, improper communication, and other issues that can also hinder progress.
Machine Learning Operation Best Practices
Implementing the latest practices is necessary to maintain the scalability and reliability of ML solutions. We have discussed some of the top practices you can consider implementing.
Automating Repetitive Tasks for Efficiency
Automation is essential to making the MLOps most effective. Many tasks, such as feature engineering, data preprocessing, model training, deployment, etc., require a lot of time to do manually. You need to leverage tools like CI/CD pipelines to automate these tasks with minimized effort and time required for iterations.
Regularly Monitoring and Retraining Models
Machine learning models tend to degrade over time. Many factors are responsible for this, including changing user behavior, data drift, and environmental changes.
You need to monitor model performance daily to detect declining accuracy or other issues early. Tools such as TensorBoard and MLFlow, which can track metrics in real-time, are appropriate for this.
Standardizing Processes and Tools Across Teams
Standardization is vital for ensuring collaboration and consistency. By adopting a unified set of frameworks and tools, such as Docker and Kubernetes, teams can streamline workflows and minimize friction.
Need MLOps Architecture Solutions for Your Business?
We provide custom MLOps solutions to streamline machine learning operations. Optimize workflows and ensure scalability with our expert services.
Conclusion
After the above discussion, we are sure you understand the importance of MLOps architecture in creating efficient, scalable, and robust ML systems.
However, building reliable and scalable ML systems presents its own set of challenges, such as inefficient workflows, a lack of collaboration between teams, and difficulties scaling models.
With a specialized MLOps Consultant Company, you can ensure a seamless lifecycle for machine learning applications with streamlined workflows, collaboration, and automation. At Moon Technolabs, you can leverage the potential advantages of AI and machine learning platforms by adopting the right practices:
- Automated data preparation
- Model training and deployment
- Monitoring and version control
- Robust infrastructures that handle increasing data and user demands.
Get in touch with our AI Development experts for a FREE consultation.
FAQs
01
What is the primary goal of MLOps Architecture?
The main goal of MLOps architecture is to improve the process of creating, deploying, and maintaining ML models. It can improve model performance, automate workflow, improve reliability, and increase scalability.02
How does MLOps improve collaboration?
MLOps can boost collaboration by minimizing the gap between developers, data scientists, and operations teams. It creates an improved workflow for the continuous delivery, integration, and deployment of ML models. It enhances communication, speeds up the development cycle, and improves model accuracy.03
What tools are essential for MLOps?
Some popular tools necessary for MLOps include CI/CD tools, Kubernetes, Docker, and Git. Prometheus and MLflow are vital for tracking model performance.04
How does MLOps differ from traditional DevOps?
MLOps is different from traditional DevOps in terms of its core focus on managing and automating ML workflows, model training, data handling, and deployment. On the other hand, DevOps mainly handles software development and infrastructure.
Jayanti Katariya is the CEO of Moon Technolabs, a fast-growing IT solutions provider, with 18+ years of experience in the industry. Passionate about developing creative apps from a young age, he pursued an engineering degree to further this interest. Under his leadership, Moon Technolabs has helped numerous brands establish their online presence and he has also launched an invoicing software that assists businesses to streamline their financial operations.
Submitting the form below will ensure a prompt response from us.
We refine our expertise to deliver innovative business solutions.




205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United States
13500 Long Is Dr, Pflugerville, TX 78660, USA
C/105 Ganesh Meridian, S.G. Highway, Ahmedabad, GJ 380060
Ayse D.
Co-Founder“ I highly recommend Moon Technolabs as the quality of service is wonderful. We have hired this company to develop the product based on some complex & technical issues. We get the best quality services as compared with others in the market. Huge Thanks to Moon Technolabs as the team is always ready to give the solution all time.”
Justin G.
Founder & CEO“ Moon Technolabs is a pioneer in the WebRTC based project as they have fixed complicated segments of the module by fulfilling different product lines by providing 24X7 customer support. We really recommended Moon Technolabs as they are able to develop products as per the module deadline and project timeline.”
Flavio S.
Founder & Managing Director“I am happy to recommend Moon Technolabs for their app development services. They successfully developed apps for me, and I am highly satisfied with the overall outcomes. The development team has swiftly addressed the issues with responsive and effective communication to understand the requirement quickly and actively resolve the back-and-forth problems that arose...”
Jay M.
Founder & CEO“Moon Technolabs is the best company that provides advanced apps and websites development services in the USA and Europe. I am a newbie to develop my app with an external team. I am really happy to work with them as I am not that much mobile apps user. Here, the team and specially the CEO of Moon Technolabs helps me to let me know about the benefits of my app to generate revenue....”




Our Offices
India
C/105 Ganesh Meridian,S.G. Highway, Ahmedabad, GJ 380060USA
205 N Michigan Avenue, #810, Chicago, 60601, Illinois, United StatesContact Information



